HOME 피플 아지트 지식 큐레이션
3534
SPSS, SAS, AMOS, STATA, Python, R 통합 워크플로우로
구현하는 고급 논문통계(설문조사) 분석 보고서
1. 서론
1.1 글의 목적 및 배경
현대 학술 연구 환경은 과거의 단일 변인·단순 통계 분석을 넘어,
복합적 연구 설계와 대규모 데이터 처리 역량을 요구합니다. 따라서 연구자는 데이터
수집에서부터 통계 모델링, 결과 해석에 이르는 전 과정을 체계적으로 관리해야 합니다.
1. 연구자 관점: 직접 분석 역량이 부족할 때 외부 전문가에게 의뢰할 때 검토해야 할 핵심 포인트
2. 전문가 관점: 분석 수행 시 놓치기 쉬운 품질 관리 절차와 커뮤니케이션 전략
3. 시장 관점: 최신 통계 기법·자동화 도구 트렌드 이해
1.2 논문통계의 정의 및 의의
‘논문통계’는 단순히 숫자를 계산하는 작업이 아닙니다.
• 가설의 객관적 검증 수단: 예컨대, 신약 효과를 입증하기 위해서는 실험군·대조군 간
차이를 단순 비교가 아닌 통계적 유의성 검정(t-검정, ANOVA)으로 확립해야 합니다.
• 재현 가능한 연구 기반: 코드와 데이터 처리 과정을 문서화함으로써 제3자 검증과 재현성이 보장됩니다.
• 연구 결과의 사회적 신뢰 확보: 학술지 게재 심사에서 통계적 엄밀성은
연구의 가치를 좌우하는 핵심 심사 요소입니다.
1.3 연구 통계 서비스의 필요성과 트렌드
• 고도화된 분석 수요: 머신러닝·딥러닝이 일반화되면서,
예측 모델 평가(ROC·AUC, 교차검증)나 클러스터링 기반 탐색적 분석이 빈번하게 요청됩니다.
• 원격 협업 체계 확장: GitHub·Notion·Zoom 같은 원격 협업 툴을 통해,
시간·공간 제약 없이 연구자와 분석가가 실시간으로 결과를 검토하고 수정합니다.
• 자동화·AI 도구 대중화: R Markdown·Jupyter Notebook으로 보고서 자동 생성,
AutoML로 반복적 모델링을 자동화하여 효율을 극대화합니다.
2. 논문 통계 서비스 시장 동향
2.1 학술 연구 환경 변화와 외부 분석 수요
• 인터·멀티디스플리너리 연구 증가
• 사회과학과 AI가 결합된 ‘디지털 휴머니티즈’, 보건학과 데이터 사이언스가 만나는
‘디지털 헬스케어’ 등 다학제적 프로젝트에서 통계 전문가가 협업 파트너로 필수
• 데이터 규모 폭발
• 웨어러블 기기 센서 데이터, 온라인 설문·로그 데이터가 기가바이트 단위로 축적
• 빅데이터 플랫폼에 익숙한 분석가가 아니면 직접 처리·정제에만 수주가 소요
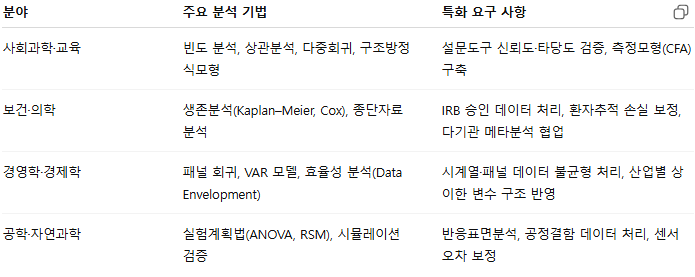
2.2 연구 분야별 통계 서비스 수요 특징
3. 제공 서비스 유형별 심층 분석
3.1 데이터 수집 및 전처리
데이터 전처리는 이후 분석 결과의 품질을 좌우하는 가장 기초적이면서도 중요한 단계입니다.
특히 결측치와 이상치는 모델링 기법마다 가정 위배의 주원인이 되므로,
적절한 방법을 선택하여 처리해야 합니다.
결측치(Missing Data) 처리
• 단순 제거 (Listwise Deletion)전체 샘플 중 결측값이 차지하는 비율이 극히 낮고(5% 미만)
무작위로 발생(MCAR)했다고 판단될 때 유효합니다. 샘플 수 감소로 인한 통계적 검정력 손실이 작아,
빠르고 간단하게 결측 케이스를 제거할 수 있습니다.
• 평균·중앙값 대체 (Mean/Median Imputation)MCAR뿐 아니라 일부 MAR(무작위가 아닌)
상황에도 적용 가능합니다. 예컨대 설문 응답 중 특정 항목이 누락된 경우,
해당 변수의 평균 또는 중앙값으로 대체함으로써 분포 왜곡을 최소화합니다.
다만, 데이터 분산이 과소추정된다는 단점이 있어 주의가 필요합니다.
• 다중대체법 (MICE: Multiple Imputation by Chained Equations)결측 패턴이 MAR 또는
MNAR(무작위 아님)일 때, 관측치에 기반해 여러 번 대체값을 생성한 뒤 이들의 평균을
최종값으로 사용합니다. 각 대체본마다 독립 분석을 수행하고 결과를 통합하기에,
결측에 따른 불확실성을 반영할 수 있습니다.
이상치(Outlier) 탐지 및 처리
• 시각화 기법박스플롯(Boxplot)과 산점도(Scatterplot)는 이상치 여부를 직관적으로
파악할 수 있는 대표적 도구입니다. 예컨대 박스플롯의 수염(whisker)을 벗어나는
점들은 우선적으로 검토 대상이 됩니다.
• 고전적 기법 (Z-score Filtering)각 데이터에 대해 표준 정규분포 상의 위치(Z-score)를 계산한 뒤,
절대값이 3을 초과하는 관측치를 이상치로 간주해 필터링합니다.
통계적 근거가 명확하지만, 분포가 비정규적일 경우 과도 검출 또는 미검출이 발생할 수 있습니다.
• 로버스트 기법 (RANSAC 회귀)RANSAC(Random Sample Consensus)은 모델을 반복적으로
추정하면서, 데이터와 적합도가 낮은 관측치를 ‘아웃라이어’로 자동 식별합니다.
회귀 분석이나 분류 모델에 앞서 적용하면, 이상치 제거 후 보다 안정적인 파라미터 추정이 가능합니다.
변수 변환(Transformation)
• 로그 변환(Log Transform)우측으로 치우친(skewed) 분포를 정규에 가깝게 만들어
선형 모형의 가정을 만족시키는 데 사용합니다. 예를 들어 소득·매출액처럼 넓은
스케일을 갖는 연속형 변수에 효과적입니다.
• 표준화(Standardization)변수별 단위 차이를 제거하고, 평균을 0·표준편차를 1로 조정합니다.
서로 다른 척도 변수를 함께 다루는 회귀 분석이나 거리 기반 알고리즘(K-means 등)에서
비교 가능성을 보장합니다.
• 범주화(Binning)연속형 변수를 의미 있는 구간(예: 연령대, 소득구간)으로 분할하여 분석합니다.
예컨대 20대·30대·40대별 소비 패턴 비교처럼, 그룹 간 차이를 검정하기에 용이합니다.
3.2 기술통계 및 탐색적 자료 분석(EDA)
EDA(Exploratory Data Analysis)는 본격적 모형링 이전에 데이터의 구조와 특성을 파악하여,
후속 분석 방향을 결정하는 단계입니다.
중심 경향 측정
• 평균(Mean)과 중위수(Median)를 함께 살펴보면 분포의 비대칭도를 가늠할 수 있습니다.
예를 들어 평균이 중위수보다 크게 나타나면 우측으로 긴 꼬리를 가진 분포임을 의미합니다.
분포 확인
• 히스토그램(Histogram)과 커널 밀도 추정(KDE: Kernel Density Estimate)은 단일 변수의
분포 형태(단봉·다봉 등)를 시각화합니다. 다봉 분포가 관찰되면, 잠재적 하위집단(subgroup)
존재를 의심하고 군집 기법을 검토할 수 있습니다.
교차 분석(Cross-Tabulation)
• 범주형 변수 간 연관성을 확인할 때 분할표(contingency table)와
모자이크 플롯(mosaic plot)을 활용합니다.
예컨대 성별·구매여부 교차표를 통해 두 변수 간 의존성을 카이제곱 검정으로 검증할 수 있습니다.
상관관계(Correlation)
• 피어슨(Pearson)∙스피어만(Spearman) 계수를 계산해 변수 간 선형∙비선형 상관 정도를 평가합니다.
상관행렬 히트맵(heatmap)을 통해 여러 변수 간 패턴을 빠르게 파악할 수 있으며,
과도한 다중공선성이 감지되면 차원축소(PCA)나 변수제거를 고려합니다.
3.3 가설검정
가설검정은 연구자가 세운 통계적 가설(null vs. alternative)을 검증하여,
집단 간 차이나 변수 간 관계의 통계적 유의성을 확인하는 과정입니다.
t-검정 (t-Test)
• 먼저 Levene’s test로 집단 간 분산 동질성(equal variance)을 확인합니다.
• 독립표본 t-검정(Independent t-test): 두 개의 독립된 집단 평균 차이를 검정합니다.
• Welch’s t-검정: 등분산 가정이 위배된 경우 사용하며,
자유도 조정으로 보다 정확한 p-값을 제공합니다.
일원배치 분산분석 (One-Way ANOVA)
• 세 개 이상의 집단 간 평균 차이를 검증하며, 사후검정(post-hoc)으로
Tukey HSD나 Scheffé test를 사용하여 구체적으로 어떤 집단 간 차이가 유의한지 확인합니다.
비모수 검정 (Nonparametric Tests)
• 데이터가 정규분포 가정을 충족하지 않거나, 관측치가 순위 데이터일 때
Mann–Whitney U, Kruskal–Wallis 검정을 적용합니다. 이들 검정은
순위 기반이므로 이상치나 분포 왜곡에 덜 민감합니다.
3.4 회귀분석·고급 통계 기법
회귀분석은 독립변수가 종속변수에 미치는 영향을 정량적으로 파악하는 핵심 도구이며,
반응표면분석(RSM)은 최적화 문제 해결에 특화됩니다.
다중 회귀분석 (Multiple Regression)
• 변수 선택 기법(전진·후진·단계적 회귀)을 활용해 과적합(overfitting)을 방지합니다.
• 분산팽창지수(VIF)로 다중공선성(multicollinearity)을 점검,
VIF > 10일 경우 공선성 문제로 간주하고 변수를 재설계합니다.
로지스틱 회귀 (Logistic Regression)
• 이분형 종속변수(예: 합격/불합격, 구매/비구매) 예측 모델로,
혼동행렬(confusion matrix)·정밀도(precision)·재현율(recall)·F1 점수 등의 지표로 분류 성능을 평가합니다.
• 임계값(threshold) 조정으로 민감도와 특이도 간 균형을 맞추며,
ROC 곡선과 AUC(Area Under Curve)로 모델 전반의 분류 능력을 요약합니다.
반응표면분석 (RSM)
• 실험계획법(Design of Experiments, DOE) 가운데 중앙합성설계(CCD)를
통해 2차 곡면(response surface)을 모델링하여 공정 변수의 최적 조합을 찾아냅니다.
예를 들어 화학 공정의 수율 극대화, 신약 합성 조건 최적화 등에 활용할 수 있습니다.
3.5 구조방정식모형(SEM) 및 시계열 분석
구조방정식모형 (SEM)
• 확인적 요인분석(CFA)으로 잠재변수(latent construct)를 검증한 뒤,
경로분석(path analysis)으로 변수 간 인과관계를 추정합니다.
• 모델 적합도를 평가할 때 χ²/df < 3, CFI(Comparative Fit Index) >
0.95, RMSEA(Root Mean Square Error of Approximation) < 0.06을 권장합니다.
시계열 분석 (Time Series Analysis)
• ARIMA(Autoregressive Integrated Moving Average) 모델 식별 시,
ACF(Autocorrelation Function)·PACF(Partial ACF)를 활용해 모수(p,d,q)를 추정합니다.
• 계절성이 강할 경우 SARIMA(Seasonal ARIMA)로 확장하며, 예측 정확도는
MAPE(Mean Absolute Percentage Error)와 RMSE(Root Mean Square Error)로 평가합니다.
3.6 결과 시각화 및 보고서 작성
고급 시각화
• ggplot2의 페이싯(facet)·그리드(grid) 기능으로 다차원 플롯을 구성하고, Plotly를 활용해
마우스 오버(tooltip)와 줌(zoom)이 가능한 대화형 차트를 제공합니다.
예컨대, 변수별 회귀선(regression line)을 중첩해 비교하거나, 다변량 분포를 3D 산점도로 표현할 수 있습니다.
보고서 자동화
• R Markdown또는 Quarto를 통해 분석 코드, 도표, 해석을 하나의 문서로 렌더링합니다.
매개변수화된 템플릿으로 R→HTML·PDF·Word 형식의 보고서를 자동 생성하여,
버전 관리와 반복 보고서 작성 효율을 극대화합니다.
4. 통계 소프트웨어·도구 활용 전략
4.1 SPSS
SPSS는 GUI 기반의 직관적 인터페이스를 제공해, 메뉴 클릭만으로도 주요 통계 분석을 수행할 수 있습니다.
하지만 대규모·반복 분석에는 Syntax(문법) 매크로 작성이 필수적입니다.
Syntax 매크로를 이용하면 동일한 분석 과정을 스크립트
화하여, 버전 호환성 문제를 줄이고 재현성을 확보할 수 있습니다.
또한 SPSS Extension Hub를 통해 Python·R 스크립트를 호출하면,
SPSS 내에서 복잡한 데이터 전처리나 커스텀 그래프 생성이 가능합니다.
4.2 R
R은 tidyverse패키지로 일관된 문법(dplyr, ggplot2)을
제공해 데이터 전처리부터 시각화까지 워크플로우를 통합합니다.
broom패키지는 회귀·분산분석 모델 객체를 깔끔한 데이터프레임 형태로 변환해,
보고서 작성과 추가 가공을 용이하게 합니다. 대규모 파이프라인 관리를 위해서는 drake나 targets패키지를 활용해,
단계별 종속성을 자동으로 추적하고 재실행할 부분만 선별 실행할 수 있습니다.
4.3 SAS·Stata
SAS는 방대한 엔터프라이즈 환경에서 강력한 ETL(추출·변환·적재) 기능을 제공합니다.
PROC SQL로 복잡한 데이터베이스 조인을 최적화하고, DATA STEP으로 반복적
데이터 처리 로직을 구현할 수 있습니다. Stata는 .do파일로 스크립트를 관리하며,
xtreg같은 패널 데이터 전용 명령어를 제공해 시계열·패널 분석에 특화되어 있습니다.
4.4 AMOS·Python
AMOS는 SEM 모델을 GUI에서 시각적으로 구성하고, 복잡한 인과 모형을 직관적으로
설계할 수 있는 장점이 있습니다. 반면 Python은 scikit-learn으로 머신러닝 전용 알고리즘을 쉽게 적용하고,
TensorFlow·Keras연동으로 딥러닝 기반 예측 모델을 구축할 수 있습니다.
Jupyter Notebook 환경에서 코드·문서·시각화를 통합해 협업할 때 유용합니다.
5. 서비스 수행 프로세스
서비스 수행은 연구자와 분석가가 협업하여 전략적으로 진행해야
고품질 결과를 얻을 수 있는 단계입니다. 다음 다섯 단계로 구성됩니다.
5.1 요구사항 정의
• 분석 설계서(Statistical Analysis Plan, SAP) 작성
• 연구 질문 및 가설: 주효과·상호작용·조절변수까지 구체화
• 변수 목록: 종속·독립·통제 변수, 측정 척도(연속·명목·순서형) 명시
• 분석 기법 매핑: 각 가설에 대응하는 통계방법(t-검정, 회귀, SEM 등)
• 데이터 구조 예시: 샘플 CSV·데이터사전(data dictionary) 첨부
샘플 크기 계산
• G*Power 활용: 효과크기(E.S.), 유의수준(α), 검정력(1–β) 설정 후 필요한 표본 수 산출
• 다변량 디자인 고려: 공변량 개수·집단 수에 따른 검정력 보정
5.2 데이터 확보·정제
• 원천 데이터 연결
• SQL 쿼리 작성: JOIN·WHERE 절로 분석용 테이블 뷰(view) 생성
• API 연동: RESTful 호출로 실시간 수집, JSON→DataFrame 변환 스크립트 제공
버전 관리
• Git 리포지터리: 분석 코드·원시 데이터·중간 결과 파일을 커밋
• 브랜치 전략: develop–feature/eda–feature/model식으로 분리해 동시 작업
5.3 분석 수행 및 중간 검증
• 탐색적 자료 분석(EDA) 보고서 공유
• 주요 분포·상관·이상치 결과를 슬라이드 또는 노트북으로 요약
• 잠재적 가정 위배 사례(비정규성·공선성) 발견 시 즉시 피드백
코드 리뷰 & 동료 검증
• 동료 분석가 또는 외부 전문가에게 Pull Request로 스크립트 검토 요청
• 주요 함수·변환 로직에 주석과 유닛 테스트(unit test)를 추가
5.4 최종 보고서 작성
• 보고서 구조
1. 서론: 연구 배경·목적·가설 요약
2. 방법론: 데이터 수집·전처리·분석 기법 구체 기술
3. 결과: 통계치 표·그래프와 함께 해석문장 제시
4. 논의: 결과 의의·한계점·실무적 함의
5. 결론 및 제언
표·그림 일관성
• 표 번호(표 1, 표 2…)와 제목은 요약형으로, 본문 내 언급 시 “(표 1 참조)”
• 그림은 해상도 ≥300dpi, 축·범례·단위 명확 기재
통계치 표기
• 회귀계수(β), 표준오차(SE), p-값(p < 0.05 등), 신뢰구간(CI 95%)
5.5 피드백 수렴 및 사후 관리
• 질의응답(ask-me-anything) 기간: 납품 후 2주간
• 코드·데이터 패키징
• R 패키지 형태(RStudio Project) 또는 Python 가상환경(requirements.txt) 제공
무상 버그 픽스 & 경미한 재분석
• 3개월 이내 분석 로직 수정·오류 정정
• 추가 변수 투입 시 간단한 민감도 분석
6. 가격 모델 및 계약 구조
적절한 가격 모델은 연구자와 분석가 모두에게 윈윈이 되는 구조를 만들어 줍니다.
6.1 시간당 요금 vs. 프로젝트 단가
• 시간당(Time & Materials)
• 장점: 긴급 오류 수정, 소규모 진단에 유연
• 단점: 규모 큰 프로젝트 시 비용 예측 어려움
프로젝트 단가(Fixed Bid)
• 장점: 전체 예산 확정 가능, 범위 관리 용이
• 단점: 요구사항 변경 시 별도 추가 계약 필요
6.2 패키지형 vs. 멘토링형
• 패키지형(Full-Service Package)
• 분석 모델링 + 보고서: EDA, 모델 개발, 시각화, 해석이 포함된 완성본
• 가이드 문서: 코드 주석, 분석 파이프라인 다이어그램, 최종 스크립트
멘토링형(1:1 Coaching)
• 코드 튜토리얼: 실습 과제, 라이브 코딩 세션
• Q&A 세션: 연구자 맞춤형 실시간 피드백(화상·채팅)
6.3 비용 산정 요소
1. 데이터 규모: 케이스 수·변수 수
2. 기법 난이도: SEM·시계열 vs. 단순 빈도 분석
3. 보고서 분량: 레포트 페이지 수, 시각자료·부록 포함 여부
4. 긴급도: 즉시 납품(24 시간 내) 시 프리미엄 요율
5. 추가 미팅: 작업 중간·최종 프레젠테이션 포함 여부
>>>SAS, R, SPSS 통계관련 도와드립니다 >>>

7. 품질 보증 및 리스크 관리
안정적인 결과 확보를 위해서는 사전·사후 검증, 데이터 보안, 윤리 준수가 필수적입니다.
7.1 재현성 검증
• 버전 관리: Git 태그(tag)로 주요 마일스톤 스냅샷 저장
• 컨테이너화: Docker 이미지로 분석 환경 통일
• 독립 크로스체크: 제3자 분석가에게 동일 코드를 실행시켜 결과 일치 여부 확인
7.2 데이터 보안
• 암호화: AES-256으로 데이터 저장, HTTPS/TLS로 전송
• 접근 제어: 최소 권한 원칙(least privilege) 적용, IAM(Identity Access Management) 활용
• 익명화(De-identification): 개인정보(이름·주소·ID) 제거 및 가명처리
7.3 윤리·저작권
• IRB 승인 절차 준수: 인간 대상 연구 시 반드시 기관윤리심의위원회 승인 문서 확보
• 저작권 관리: 보고서·코드 라이선스 명시(예: CC BY-NC)
• 출처 인용 가이드: APA, Chicago 스타일 가이드에 따른 인용 표기
8. 사례 연구
8.1 성공 사례: NHANES 코호트 로지스틱
• 배경: 미국 국민건강영양조사(NHANES) 10년치 데이터를 이용해 고혈압 위험인자 분석
• 분석: 다중 로지스틱 회귀, 독립변수(연령·BMI·흡연여부) 투입
• 결과:
• BMI 1단위 증가 시 고혈압 오즈비 1.12 (95% CI: 1.08–1.16, p < 0.001)
• ROC AUC 0.82로 분류 모델 유효성 확인
성과: 연구논문 게재 후, 후속 임상시험에서 환자선별 기준 마련에 기여
8.2 오류 극복 사례: SPSS 매크로
• 문제: 변수명이 바뀐 뒤 매크로 Syntax 오류로 반복분석 실패
• 진단: 매크로 내부 하드코딩된 변수 참조
• 해결: 동적 변수 참조(!CONCAT함수) 적용, 매크로 매개변수(parameter)화로 유연성 확보
8.3 인터뷰 인사이트
• 현업 연구자: “초기 가설 구체화에 70% 시간을 투자했더니, 분석 결과 해석이 훨씬 매끄러웠다.”
• 경험 많은 분석가: “EDA 단계에서 변수 분포·이상치 문제를 완벽히 해결해야,
회귀·SEM 결과가 황금률에 가까워진다.”
9. 연구자·분석가를 위한 가이드라인
9.1 의뢰 전 체크리스트
• 연구 가설·변수 사전 정의서
• 최소 50~100개 샘플 데이터 예시(CSV)
• 분석 목적·우선순위(핵심 지표 KPI)
9.2 효과적인 커뮤니케이션 팁
• 마일스톤 계획: 중간 점검 일정(EDA → 모델링 → 보고서) 수립
• 공통 용어집(Glossary): 변수명·약어·단위 표준화 문서 공유
• 정기 보고: 주간 요약 리포트(이슈·해결·계획)
9.3 보고서 작성 유의사항
• Executive Summary: 비전문가도 이해 가능한 1페이지 개요
• 표·그림 부록: 코드 스니펫·분석 파이프라인 다이어그램 별도 첨부
• 한계점 및 제언: 가정 위배, 샘플 편향, 추천 후속 연구 명시
10. 결론 및 향후 전망
10.1 AI·자동화 도구의 역할 확대
• ChatGPT·GitHub Copilot: 분석 코드 초안·주석 생성 지원
• AutoML 플랫폼: H2O.ai·Auto-sklearn으로 모델 탐색·튜닝 자동화
10.2 원격 협업 환경에서의 진화
• 클라우드 기반 노트북: JupyterHub·RStudio Server로 실시간 코드·데이터 공유
• Live Collaboration: VS Code Live Share, Google Colab에서 동시 편집
10.3 미래 연구 통계 생태계
• 오픈 사이언스(Open Science): 데이터·코드 공개 저널(data journals) 증가
• 재현성(Reproducibility) 강화: 컨테이너 배포(Docker), 워크플로우 자동화(Nextflow) 확산
• 전담 조직 확충: 대학·연구소 내 데이터 사이언스 센터 설립으로, 통계 지원 인프라 고도화
부록 A. 주요 통계 용어 해설
• p-value: 영가설 기각 확률
• η² (Eta squared): 분산분석 효과크기 지표
• ICC (Intraclass Correlation): 군집 자료의 동질성 척도
부록 B. 추천 자료 목록
1. Applied Linear Statistical Models(Kutner et al.)
2. R for Data Science(Wickham & Grolemund)
3. The Elements of Statistical Learning(Hastie et al.)
4. R 패키지 문서(ggplot2, caret, lavaan) 및 공식 튜토리얼
지금 뜨는 BEST 큐레이션 글!
TOP 1 : [생존 가이드] GPT 자소서 안걸리는법 - 기술적/인간적 탐지를 우회하는 실전 리터칭 기법 및 면접 대응
TOP 2 : [합격 가이드 X 실전 AI 기술] 나만의 AI 무기 장착 - 자소서의 경험 분석부터 면접관을 사로잡는 비판적 증명법
TOP 3 : [추천! AI 검색 점령] AEO 실전 전략 및 수익화 : AI 검색 시장을 점령하는 상위 1%의 기술
TOP 4 : AI 롤플레잉 면접 독학서 챗GPT로 완성하는 실전 면접 - 면접관 소환, 꼬리 질문 방어까지, 합격 부르는 AI 대화 기술
TOP 5 : [Part 2] 제안서 작성법 – PPT(피피티) 제안서 (선택받는 사업계획서)
- 지식 큐레이션 모든 컨텐츠는 재능아지트가 기획, 생성한 컨텐츠로 무단 사용 및 침해 행위를 금지합니다. -
© 재능아지트 | All rights reserved.









㈜에스앤에스모바일
Copyrightsⓒ ㈜에스앤에스모바일. All rights reserved.



재능아지트((주)에스앤에스모바일)은 통신판매중개자이며, 판매의 당사자가 아닙니다. 상품, 상품정보, 거래에 관한 의무와 책임은 판매회원에게 있습니다.
재능아지트의 사전 서면 동의 없이 재능아지트 사이트의 일체의 정보, 컨텐츠 및 UI 등을 상업적 목적으로 전재, 전송, 스크래핑 등 무단 사용할 수 없습니다.